AI/ML
AI CommodityChain
Hours (manual research)→60 secondsdata-to-analysis latency
Commodity traders operate in a high-stakes environment where fragmented, lagging intelligence directly translates to missed opportunities. The existing workflow required analysts to spend hours manually pulling prices across different exchanges and reading through hundreds of news headlines to gauge market sentiment. This slow, labor-intensive process meant that by the time an analysis was complete, the market had often already moved. Attempting to use standard AI tools to speed this up failed because models relying on training memory confidently hallucinated market states. This daily pain of choosing between speed and accuracy could not continue in a volatile market. The specific trigger for change was a major intraday shift in energy prices that the team missed entirely while compiling their daily manual reports.
// system visuals
See It In Action
LIVE_SYSTEM_PREVIEW
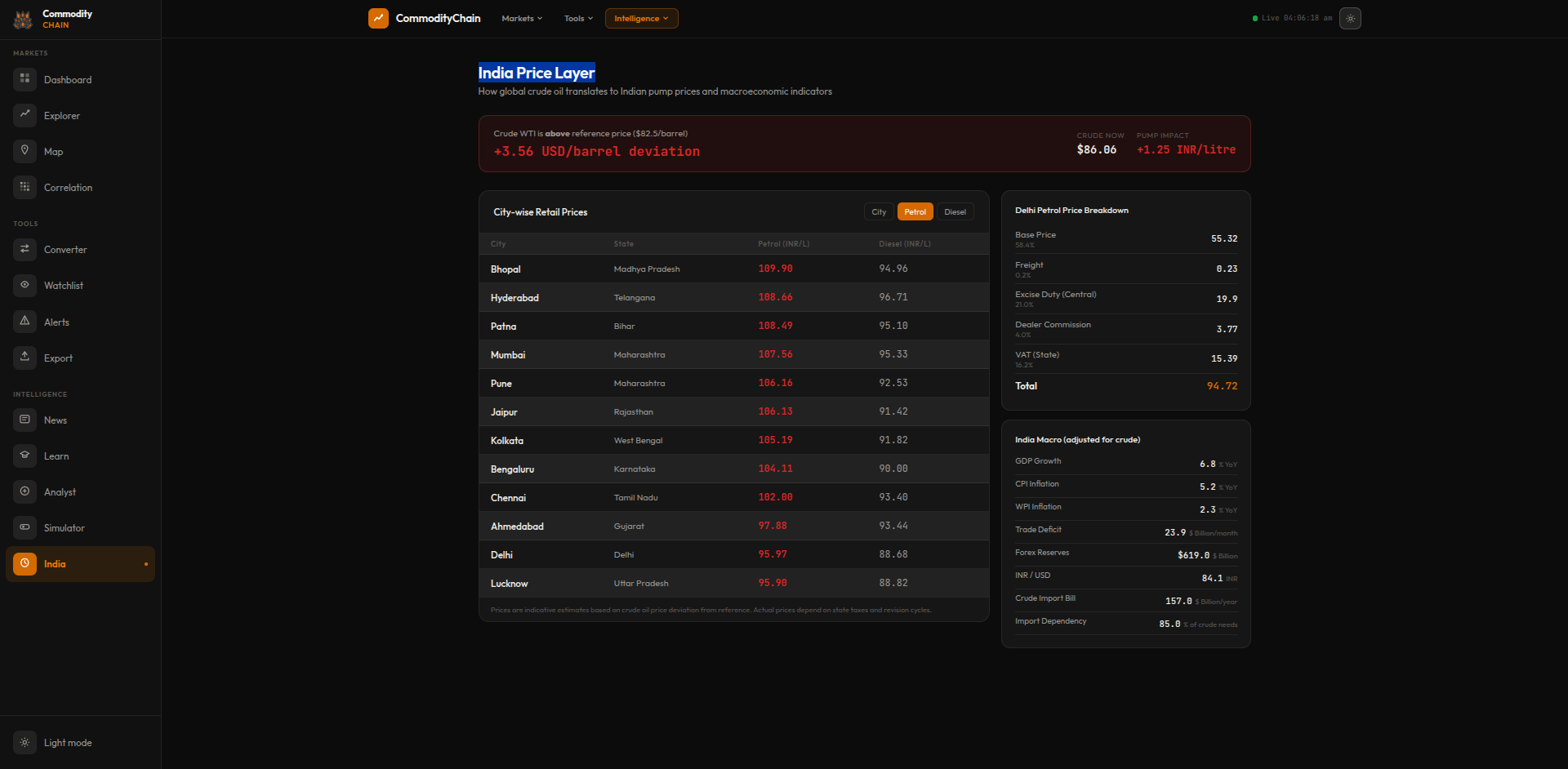
01/09
← → NAVIGATE_SYSTEM
// the problem
What Was Broken
- Analysts were manually aggregating data across dozens of disparate sources, meaning market visibility was always hours behind reality. Built an automated ingestion engine that pulls live prices and news concurrently, eliminating the manual bottleneck entirely.
- Standard LLMs used for analysis were hallucinating because they lacked live market awareness, making their financial insights dangerously unreliable. Engineered a pipeline that completely bypasses the model's training memory by injecting real-time facts directly into every prompt.
- Market correlation analysis was a tedious spreadsheet exercise that was rarely updated more than once a week. Replaced this with a dynamic Pearson correlation matrix that recalculates continuously, exposing hidden market movements instantly.
- News sentiment was tracked subjectively by individuals reading headlines across multiple browser tabs. Deployed a real-time Scrapy pipeline with a lightweight classifier that tags every headline with a concrete bullish, bearish, or neutral signal.
// required fix
- The team needed a powerful language model but could not expose proprietary trading queries to external APIs. Deployed a quantized 70B parameter model locally on Linux, ensuring complete data sovereignty and zero recurring inference costs.
- AI models were generating plausible but factually incorrect market summaries because they lacked current data. Built a context injection layer that intercepts every query, fetches live market metrics, and forces the model to analyze only the injected facts.
- Traders lacked immediate visibility into how disparate commodity markets were influencing each other intraday. Engineered a computational engine that continuously processes 30-day daily price returns to generate a live Pearson correlation heatmap.
- Tracking global macroeconomic news manually was impossible at scale, causing the team to miss critical sentiment shifts. Developed a continuous Scrapy pipeline that aggregates global headlines and automatically tags them with market impact labels.
// solution
How It Was Built
To achieve total data privacy and zero API costs, the foundation was laid by deploying a quantized Llama 3.3 (70B) model locally on a Linux server. The core innovation was the context injection pipeline, which intercepts every request to wrap it in freshly scraped market data and sentiment-tagged news before it reaches the model. For quantitative analysis, a Pearson correlation engine was built to process 30-day price returns continuously, feeding a live heatmap. The entire system is monitored by custom shell-based health checks that ensure the unattended infrastructure remains highly available, automatically recovering from memory leaks or stalled processes.
Local LLM Infrastructure — Llama 3.3 70B
- Running a 70B parameter model typically requires massive cloud infrastructure, which introduced unacceptable data privacy risks and recurring costs for this project.
- 📄 health_check.sh
Context Injection Pipeline — No Hallucinations
- The most dangerous problem with using LLMs in finance is that they confidently hallucinate numbers when asked about current market states.
- 📄 context_builder.py
Pearson Correlation Matrix Engine
- Traders intuitively knew that certain energy and metal markets moved together, but proving it required hours of manual spreadsheet work that was rarely up to date.
Real-Time News Sentiment Aggregator
- Raw news volume is overwhelming, and simply displaying a feed of headlines provided no actual analytical value to the traders.
Local LLM Infrastructure — Llama 3.3 70B
Running a 70B parameter model typically requires massive cloud infrastructure, which introduced unacceptable data privacy risks and recurring costs for this project. Cloud APIs were rejected outright due to strict internal security policies regarding proprietary trading queries. Instead, the decision was made to run a heavily quantized version of Llama 3.3 70B locally on an internal Linux server. This constraint meant managing raw memory limits and inference latency directly on the hardware. A critical problem was that local LLM instances can occasionally hang or leak memory over days of continuous operation. To mitigate this, a robust shell-based health-checking daemon was written. This script continuously polls the model's API endpoint, monitoring response latency and system memory utilization. If the endpoint fails to return a 200 OK within the expected window, the daemon automatically forcefully restarts the service and logs the event. This edge case handling unlocked the ability to run the system completely unattended, turning a fragile local experiment into a production-grade internal service.
health_check.sh
bash
#!/bin/bash
RESPONSE=$(curl -s -o /dev/null -w "%{http_code}" http://localhost:11434/api/health)
if [ "$RESPONSE" != "200" ]; then
echo "[$(date)] LLM service unhealthy — restarting"
systemctl restart ollama
fiContext Injection Pipeline — No Hallucinations
The most dangerous problem with using LLMs in finance is that they confidently hallucinate numbers when asked about current market states. Fine-tuning the model on recent data was considered but rejected because the market changes minute-by-minute, making any static fine-tune instantly obsolete. The chosen solution was strict Retrieval-Augmented Generation (RAG) via a custom context injection pipeline. Before the LLM ever sees a user's query about a commodity, the pipeline pauses the request and fires off parallel calls to fetch the live price ticker and the last 5 sentiment-tagged news headlines. It then dynamically constructs a strict system prompt containing only these facts. The model is explicitly instructed to base its analysis solely on the provided text block and to state if the data is insufficient. This architectural choice structurally prevents the model from relying on its pre-trained weights for factual assertions. The primary edge case handled was API rate limiting from the live data sources, mitigated by implementing a rapid local cache layer that holds prices for 60 seconds.
context_builder.py
python
def build_context(commodity: str) -> str:
prices = fetch_live_prices(commodity)
news = fetch_sentiment_news(commodity, limit=5)
return (
f"Current prices:\n{format_prices(prices)}\n\n"
f"Recent news (sentiment-tagged):\n{format_news(news)}\n\n"
f"Analyse market conditions for {commodity}."
)Pearson Correlation Matrix Engine
Traders intuitively knew that certain energy and metal markets moved together, but proving it required hours of manual spreadsheet work that was rarely up to date. Relying on gut feel or outdated weekly reports led to poor hedging decisions during volatile periods. The implementation involved building a Python-based computational engine that pulls 30-day daily price return data across all tracked commodities. The engine calculates a full Pearson correlation matrix dynamically every time the dashboard is loaded. This data is then rendered as an interactive heatmap on the frontend, using color intensity to instantly highlight strong positive or negative correlations. A significant technical hurdle was handling missing data points or holiday trading gaps across different global exchanges. This was mitigated by implementing forward-fill interpolation before calculating the correlations, ensuring the matrix computation never crashed due to mismatched array lengths. This step unlocked immediate, quantitative validation of macroeconomic trends for the trading desk.
Real-Time News Sentiment Aggregator
Raw news volume is overwhelming, and simply displaying a feed of headlines provided no actual analytical value to the traders. The problem was extracting the signal—whether the news was bullish or bearish—from the noise in real time. Using external sentiment APIs was rejected due to latency and cost at high volumes. Instead, a continuous scraping pipeline was built using Scrapy, deployed to run on a strict schedule across major financial news portals. As each headline is ingested, it is passed through a lightweight, locally hosted classifier model trained specifically on financial terminology. This classifier tags each item with a market impact label (bullish, bearish, or neutral) before it hits the database. The edge case of sites changing their HTML structure and breaking the scrapers was handled by building explicit failure detection that alerts the engineering team immediately if expected CSS selectors return null. This pipeline ensured that the LLM context injection always had the most current, pre-processed sentiment data available.
// results
What Changed
The platform reduced the end-to-end latency from market event to comprehensive dashboard analysis to just 60 seconds. By strictly enforcing context injection, the critical problem of LLM hallucination in financial reporting was entirely eliminated. Traders now rely on a unified interface that delivers both quantitative correlation signals and qualitative sentiment intelligence instantly. This infrastructure proved that AI can be trusted in high-stakes environments, provided it is structurally prevented from guessing.
Data-to-analysis latency
Hours (manual research)
→
0
Real-time
LLM hallucination risk
High (training-memory-only)
→
0
Context injection
Correlation analysis
Manual spreadsheets
→
0
Automated
"Built the infrastructure that makes AI financial analysis actually trustworthy — by never letting the model guess when it can be given the facts."