DevOps
Cloud Infrastructure Automation Platform
4 weeks (manual)→15 minutesenvironment provisioning time
Provisioning a new cloud environment required opening dozens of tickets across networking, database, and compute teams, taking over four weeks of manual effort. Because these environments were configured by hand over time, configuration drift was a structural guarantee—no two environments were identical. This inconsistency made staging entirely unreliable as a test environment; deployments would succeed there but fail catastrophically in production due to unnoticed networking differences. Furthermore, there was absolutely no audit trail; when infrastructure broke, debugging meant guessing who had logged into the console and what they had changed. The specific trigger for this project was a production outage caused by an undocumented security group change that took six hours just to identify because no version control existed.
// system visuals
See It In Action
LIVE_SYSTEM_PREVIEW
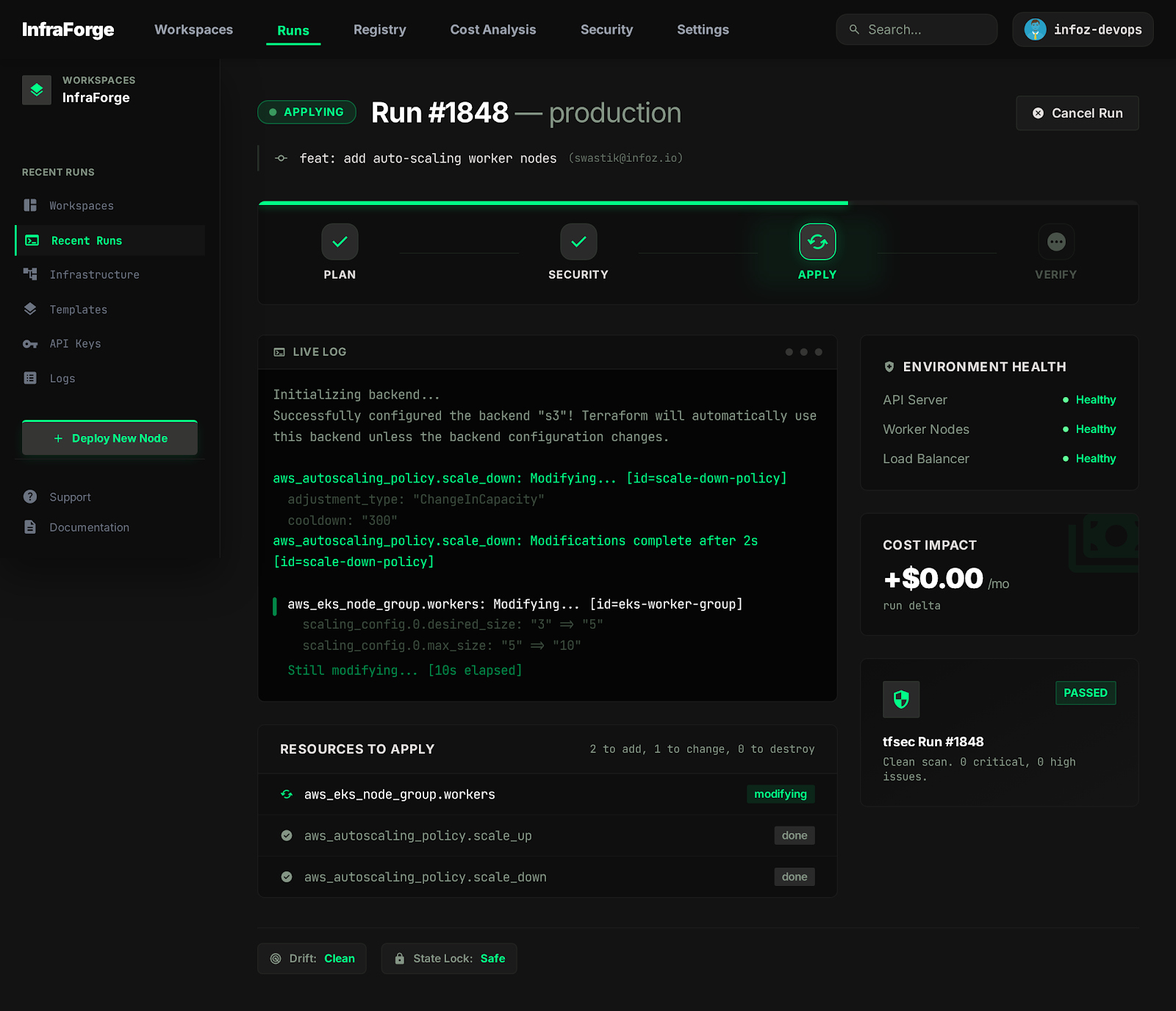
01/04
← → NAVIGATE_SYSTEM
// the problem
What Was Broken
- Provisioning a new cloud environment required over four weeks of manual ticket ping-pong across multiple siloed teams. Replaced this entire workflow with a centralized Infrastructure-as-Code repository, reducing provisioning to a 15-minute automated run.
- Configuration drift between dev, staging, and prod meant that testing in staging provided false confidence, leading to frequent deployment failures in production. Codified all tiers to deploy from the exact same modules, enforcing absolute structural parity across environments.
- There was zero audit trail for infrastructure changes; finding out who changed a routing rule and why required interrogating the team. Moved all infrastructure state to Git, meaning every change now has an author, a timestamp, and an approved pull request attached to it.
- When bad infrastructure changes were deployed, rollback meant frantically attempting to remember and revert the manual clicks in the cloud console. Introduced automated pipeline rollbacks that restore the previous known-good state via versioned Terraform applies.
// required fix
- The engineering team needed a standardized way to provision resources without constantly reinventing the wheel for every new service. The task was to build a centralized, versioned repository of reusable IaC modules covering standard compute, networking, and database patterns.
- Infrastructure changes were previously deployed blindly without any automated validation or peer review. The objective was to build a CI/CD pipeline that runs security scans and a speculative plan on every pull request, forcing changes through the same rigorous review as application code.
- Despite policies against it, engineers occasionally made manual emergency fixes in the cloud console, immediately causing the actual state to diverge from the documented state. The task required implementing scheduled drift detection to explicitly alert when the live environment no longer matched the code.
- When a bad configuration was applied, there was no straightforward way to revert the environment to a working state quickly. The goal was to build automated rollback mechanisms into the CI/CD pipeline, ensuring infrastructure could be safely reverted in minutes upon failure.
// solution
How It Was Built
The foundation of the solution was building highly modular, parameter-driven Terraform modules that abstracted the complexity of standard deployment patterns. This code was orchestrated entirely via GitHub Actions, which managed the remote state centrally with strict DynamoDB locking to prevent race conditions during concurrent deployments. To ensure security and compliance, tools like tfsec were integrated directly into the CI pipeline to block any pull request that introduced misconfigurations, such as open security groups. This setup shifted infrastructure management from an opaque operational task into a transparent, collaborative engineering process.
Modular IaC with Remote State
- Before this implementation, teams copy-pasted infrastructure configurations, leading to subtle bugs and immense technical debt whenever a standard pattern needed updating.
CI/CD Pipeline for Infrastructure
- Historically, infrastructure changes were applied directly from engineers' laptops, meaning there was no guarantee that the applied code matched what was in version control.
- 📄 .github/workflows/infra.yml
Modular IaC with Remote State
Before this implementation, teams copy-pasted infrastructure configurations, leading to subtle bugs and immense technical debt whenever a standard pattern needed updating. The immediate problem was that updating a core networking rule required manually tracking down and editing every copy-pasted instance across the codebase. The chosen solution was to build highly opinionated, reusable Terraform modules for standard architectural patterns (e.g., standard web-tier compute, isolated RDS instances, strict VPC routing). By parameterizing variables like instance size and environment tags, a single module could safely provision dev, staging, and prod. We utilized remote state management stored centrally in an S3 bucket, heavily coupled with DynamoDB state locking. This explicit locking was critical; it categorically prevented the disastrous edge case of two engineers merging infrastructure PRs simultaneously and corrupting the state file. This foundational step unlocked the ability to scale infrastructure management safely across multiple concurrent teams without race conditions.
CI/CD Pipeline for Infrastructure
Historically, infrastructure changes were applied directly from engineers' laptops, meaning there was no guarantee that the applied code matched what was in version control. This lack of transparency made code reviews functionally useless. The solution was to revoke direct apply permissions from developers and orchestrate all applies exclusively through a GitHub Actions CI/CD pipeline. The pipeline was engineered to run a `terraform plan` and a `tfsec` static analysis check on every single pull request. Crucially, the pipeline automatically formats and posts the speculative plan output directly as a comment on the PR. This forces the reviewer to see exactly what resources will be created, modified, or destroyed before clicking merge. To handle the edge case of an applied plan failing midway due to cloud provider API limits, the pipeline was configured to retain the locked state and alert the DevOps team immediately for manual intervention. This pipeline ensured that infrastructure changes became visible, reviewed, and deeply predictable.
.github/workflows/infra.yml
yaml
on:
pull_request:
paths: ['infra/**']
jobs:
plan:
runs-on: ubuntu-latest
steps:
- name: Security scan
run: tfsec ./infra --soft-fail=false
- name: Plan
run: cd infra && terraform plan -out=tfplan
- name: Comment plan on PR
uses: borchero/terraform-plan-comment@v1// results
What Changed
The automated pipeline collapsed the time required to provision a completely new, production-ready environment from a sluggish four weeks down to a deterministic 15 minutes. Configuration consistency is now structurally enforced across all tiers, completely eliminating the 'works in staging' deployment failures. Every single infrastructure change is now versioned, peer-reviewed, and fully auditable via Git history. This fundamentally shifted the engineering culture; teams stopped fearing infrastructure changes and started treating them as routine, low-risk operations.
Environment provisioning time
4 weeks (manual)
→
0
~270× faster
Configuration consistency
Unknown (drift)
→
0
Guaranteed
Infrastructure audit trail
None
→
0
Complete visibility
"Infrastructure code lives in Git, gets reviewed like application code, and deploys automatically. The team stopped being afraid of infrastructure changes."