Automation
Enterprise Web Scraper — 10,000+ Products Tracked
Manual spot-checks→10,000+ continuouslyproducts tracked
The business was making critical pricing and inventory decisions based on competitor data that was manually spot-checked by different people at irregular intervals. This approach meant that data was often days or weeks old, and coverage was severely limited to whatever a person had time to look up that week. Because there was no consistent historical baseline, performing any meaningful trend analysis or predictive modeling was mathematically impossible. Furthermore, early attempts at automated scraping consistently failed because single-tool approaches broke completely when encountering modern, JavaScript-heavy single-page applications. The daily pain was that the pricing team knew their data was bad, but lacked the engineering resources to fix the ingestion pipeline.
// system visuals
See It In Action
LIVE_SYSTEM_PREVIEW
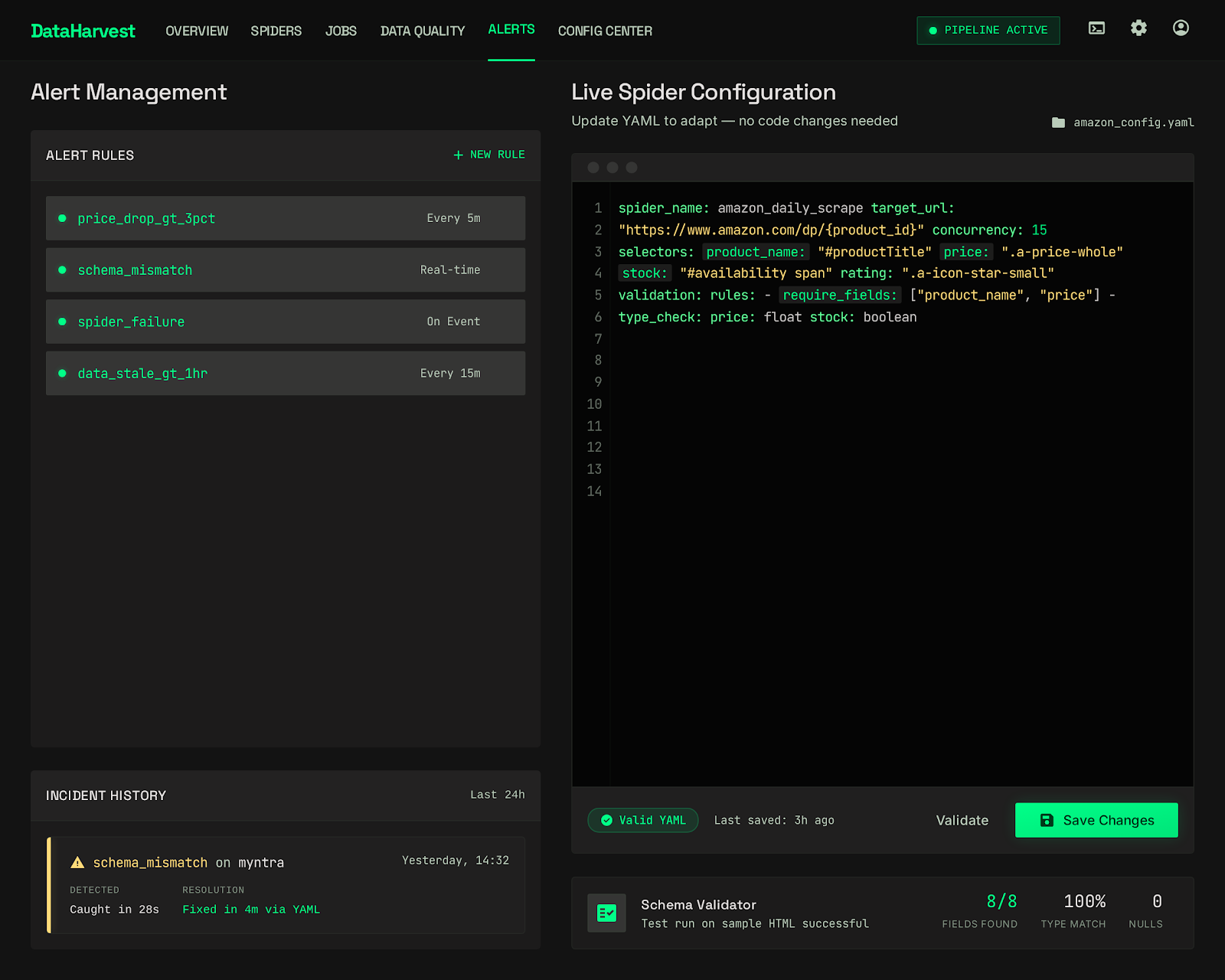
01/03
← → NAVIGATE_SYSTEM
// the problem
What Was Broken
- Manual data collection meant that by the time a pricing report was compiled, the market had already shifted, making the data stale and unactionable. Replaced this with a continuous pipeline that pulls data on a strict, automated schedule.
- Coverage was severely restricted by human bandwidth, typically tracking fewer than 500 high-priority items inconsistently. Scaled the architecture to track over 10,000 products continuously without requiring any human intervention.
- There was absolutely no consistent historical baseline recorded, making long-term trend analysis or seasonal price tracking completely impossible. Engineered the pipeline to output structured, time-series data ready for immediate insertion into a data warehouse.
- Existing single-tool scrapers were brittle, constantly breaking silently when target sites deployed JavaScript-rendered pages. Built a hybrid architecture that intelligently routes requests to headless browsers only when JavaScript execution is strictly necessary.
// required fix
- The pipeline needed to seamlessly process both simple static pages and complex single-page applications. The task was to integrate Scrapy and Selenium into a unified hybrid architecture that leverages speed when possible and rendering power when necessary.
- The business required a massive increase in scale, moving from hundreds of manually checked items to tracking over 10,000 products continuously. The goal was to build a distributed scheduling system that could handle this volume without triggering IP bans or rate limits.
- Silent data failures were polluting downstream reports because scrapers would pull empty strings when CSS selectors changed. The objective was to build a rigorous validation layer that catches missing fields and halts the pipeline immediately, failing loudly.
- Analysts were spending hours cleaning raw HTML dumps before they could actually analyze the numbers. The task was to ensure the pipeline natively outputs clean, strictly typed DataFrames directly into the reporting infrastructure.
// solution
How It Was Built
The pipeline was engineered as a dynamic Scrapy and Selenium hybrid, intelligently routing requests based on target site requirements to optimize for both speed and rendering capabilities. Instead of hardcoding fragile CSS selectors directly into spider logic, all target mappings were abstracted into version-controlled configuration files. This decoupling allowed for rapid adaptation to site layout changes without altering core application code. The most critical implementation was the fail-loud validation layer; every single scraped payload is verified against an expected schema. If critical fields like price or availability are missing due to a DOM change, the payload is rejected and an immediate alert is fired to the engineering team.
Scrapy + Selenium Hybrid Architecture
- The immediate technical challenge was that relying purely on Selenium for 10,000+ pages was too slow and resource-intensive, while relying purely on Scrapy meant missing critical data rendered via JavaScript APIs.
- 📄 pipeline/router.py
Fail Loud — No Silent Data Loss
- The most dangerous issue with web scraping is silent failure—when a site updates its CSS classes, the scraper might successfully execute but extract empty strings, quietly corrupting the downstream database.
Configurable Field Mappings
- Websites change their layouts constantly, meaning scrapers require frequent maintenance.
Scrapy + Selenium Hybrid Architecture
The immediate technical challenge was that relying purely on Selenium for 10,000+ pages was too slow and resource-intensive, while relying purely on Scrapy meant missing critical data rendered via JavaScript APIs. The solution was engineering a hybrid router. The system initially dispatches a lightweight HEAD or fast GET request using Scrapy to analyze the initial response payload. If the expected data fields are present in the raw HTML, the fast Scrapy spider handles the extraction. However, if the router detects that the page requires DOM hydration (identified via missing fields in the raw HTML but expected based on configuration), it dynamically hands the URL over to a pool of headless Selenium browsers. A major edge case handled here was managing zombie Selenium processes that failed to close after encountering infinite loading loops on poorly built target sites; a strict timeout and process-reaping mechanism was implemented to ensure the scraping nodes didn't run out of memory. This hybrid approach unlocked the ability to scale massively while maintaining the capability to scrape modern web applications.
pipeline/router.py
python
def route_spider(url: str, config: dict) -> Spider:
response = requests.head(url)
if requires_js_render(response, config['expected_fields']):
return SeleniumSpider(url, config)
return ScrapySpider(url, config)Fail Loud — No Silent Data Loss
The most dangerous issue with web scraping is silent failure—when a site updates its CSS classes, the scraper might successfully execute but extract empty strings, quietly corrupting the downstream database. To solve this, a strict validation layer was implemented immediately after extraction and before database insertion. Every scraped item is checked against a defined schema that enforces type and presence constraints (e.g., price must be a float > 0, title must be a non-empty string). If the data fails this validation, the pipeline does not write it to the database. Instead, it flags the specific target URL and configuration as broken, halts further processing for that specific domain to save resources, and fires an immediate PagerDuty alert. This explicit fail-loud design guarantees that analysts are never looking at missing or corrupted data—they know instantly when a data source requires maintenance.
Configurable Field Mappings
Websites change their layouts constantly, meaning scrapers require frequent maintenance. Hardcoding CSS selectors and XPath expressions deeply inside the Python spider code meant that every minor site update required a full code review and application redeployment. The solution was to abstract all extraction rules into separate, easily readable YAML configuration files. The Python engine reads these configs dynamically at runtime. When a target site changes its design, updating the scraper is as simple as editing a single line in a YAML file and committing the change. A significant edge case was handling A/B testing on target sites where multiple layouts might be served randomly. This was mitigated by allowing the configuration files to hold arrays of fallback selectors; the engine sequentially attempts each selector until it successfully extracts the validated data. This design pattern drastically reduced maintenance overhead and allowed non-engineers to occasionally fix broken scrapers.
// results
What Changed
The implemented pipeline successfully tracks over 10,000 products continuously, entirely replacing the fragmented manual collection process. By guaranteeing data freshness and explicitly eliminating silent data failures, the business teams transitioned from reacting to stale pricing data to proactively analyzing structured, verified trends. This robust data foundation fundamentally changed how the company approached competitive pricing, replacing guesswork with high-fidelity market intelligence.
Products tracked
Manual spot-checks
→
0
Full coverage
Data freshness
Days to weeks old
→
0
Always current
Silent data failures
Undetected
→
0
Eliminated
"Pricing decisions stopped being made on stale guesses. The data is there, it is current, and it is trusted."