Automation
Automated Document Management System
Manual search, minutes→Predictable structure, secondsdocument retrieval
The organization relied on an unstructured shared drive for critical document storage, resulting in a chaotic, deeply nested folder hierarchy with no enforced naming conventions. Because every employee saved files according to their own personal logic, the shared drive became effectively unsearchable; finding an invoice or a finalized contract required manually clicking through dozens of folders. Duplicates accumulated silently, leading to dangerous version control issues where outdated documents were frequently used by mistake. When naming conflicts occurred, critical files were occasionally overwritten without warning. The daily reality was that document retrieval was a massive drain on productivity, and the lack of structural integrity posed a significant compliance risk.
// system visuals
See It In Action
LIVE_SYSTEM_PREVIEW
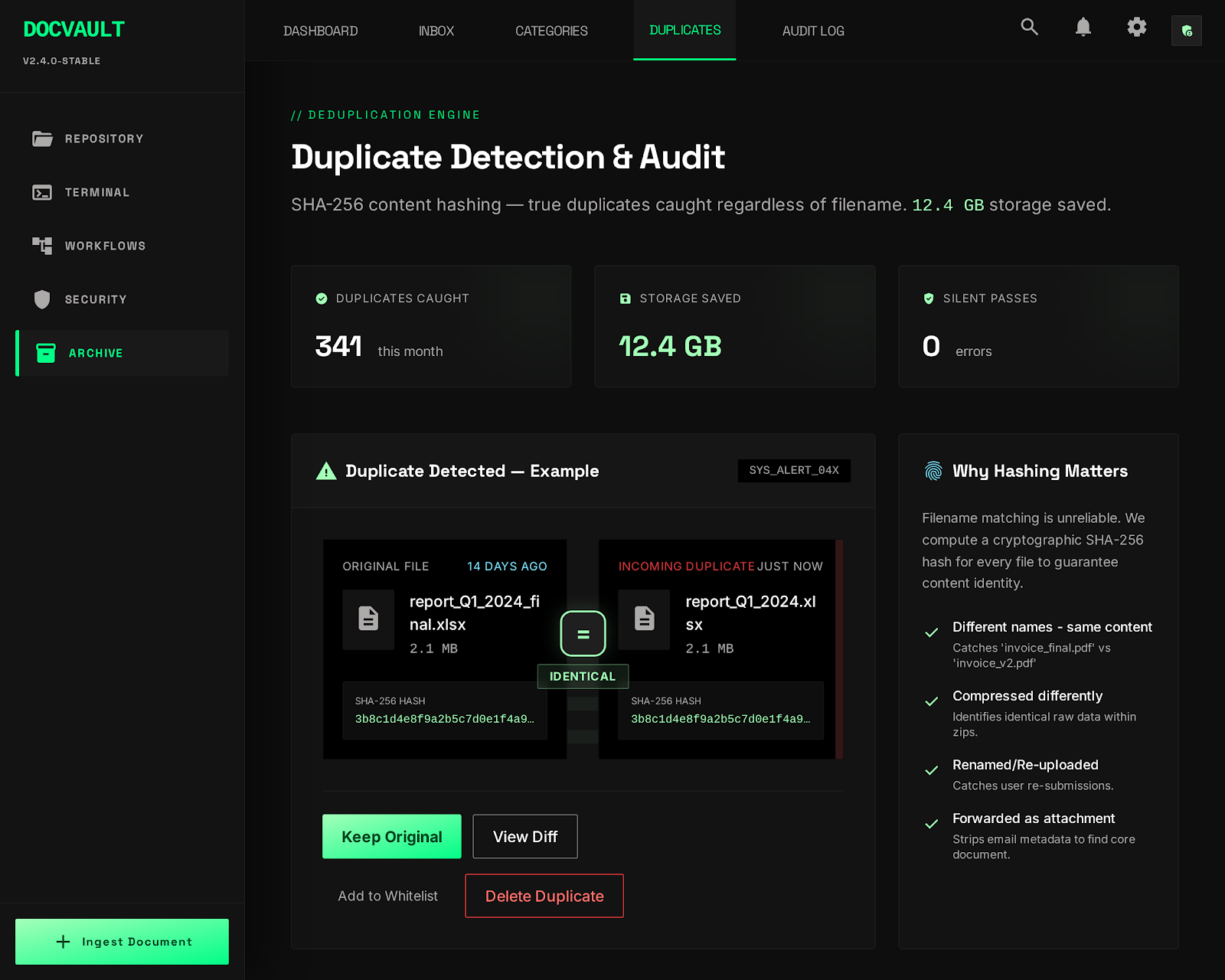
01/02
← → NAVIGATE_SYSTEM
// the problem
What Was Broken
- Employees lacked standard naming conventions, meaning files were saved haphazardly, making search practically impossible. Engineered a rule-based engine that automatically categorizes and normalizes file placement based on content and patterns.
- Exact duplicates accumulated silently across different folders, causing severe version control confusion and wasting storage. Implemented hash-based file comparison to actively detect and flag duplicates regardless of what they were named.
- Naming conflicts were resolved inconsistently, occasionally leading to the catastrophic overwriting of critical documents. Built explicit conflict resolution logic that safely appends timestamp suffixes to ensure zero data loss.
- Document retrieval times were measured in frustrating minutes rather than seconds, severely impacting operational velocity. Restructured the entire repository into a predictable, machine-readable format that supports instantaneous retrieval.
// required fix
- The unstructured repository was a major compliance and operational risk. The goal was to build a rule-based system that intercepts documents at ingestion and intelligently routes them to a strictly enforced directory hierarchy.
- Silent failures in categorization lead to lost documents. The task was to ensure that files that defied classification were explicitly routed to a human review queue rather than being buried in the wrong folder.
- Duplicate files were causing versioning nightmares. The objective was to implement robust deduplication logic utilizing cryptographic hashing to identify identical content regardless of the filename.
- The system needed to be extensible. The task required designing a flexible ruleset architecture where new categorization logic could be added easily without altering the core processing engine.
// solution
How It Was Built
A powerful rule-based classification engine was developed in Python, designed to process documents immediately upon ingestion. The engine evaluates each file against an ordered hierarchy of rules, utilizing complex regex patterns and metadata extraction to determine the correct destination. To address versioning and data loss, explicit edge-case handling was implemented: naming conflicts are resolved safely with timestamp suffixes, and true duplicates are identified via SHA-256 hash comparisons. Files that fail to match any rule are actively routed to a dedicated review queue, complete with an execution log detailing exactly why classification failed, ensuring absolute transparency.
Rule-Based Classification Engine
- The primary technical challenge was building a classification engine that was flexible enough to handle massive variance but strict enough to be reliable.
- 📄 classifier.py
Edge Case Handling — Conflicts and Duplicates
- Handling the physical movement of files introduced significant edge cases regarding data safety.
Rule-Based Classification Engine
The primary technical challenge was building a classification engine that was flexible enough to handle massive variance but strict enough to be reliable. The solution was an ordered rule-engine architecture. When a document enters the ingestion queue, it is sequentially evaluated against a defined set of rules. The engine first attempts fast, high-confidence matching using regex on the filename. If that fails, it falls back to analyzing the file extension combined with basic metadata. If the file remains ambiguous, the engine samples the actual text content for specific keyword clusters. The critical design decision was that the engine never guesses; if a document does not explicitly match a rule, it is securely moved to a 'review_queue' directory. This fail-loud approach guarantees that documents are never silently miscategorized, maintaining the absolute integrity of the organized repository.
classifier.py
python
RULES = [
Rule(pattern=r'invoice_\d+', category='finance/invoices'),
Rule(pattern=r'contract_.*\.pdf', category='legal/contracts'),
Rule(pattern=r'report_\d{4}', category='reports/annual'),
]
def classify(filepath: Path) -> str:
for rule in RULES:
if rule.matches(filepath):
return rule.category
return 'review_queue' # Never silently miscategorizeEdge Case Handling — Conflicts and Duplicates
Handling the physical movement of files introduced significant edge cases regarding data safety. Simply moving a file risks overwriting an existing document with the same name. To solve this, explicit conflict resolution logic was engineered. If a naming collision is detected in the destination folder, the system safely appends a microsecond timestamp suffix to the incoming file. Furthermore, the system addresses the rampant duplicate problem by generating a SHA-256 hash of the file contents before processing. If the hash matches an existing document anywhere in the repository, the file is immediately flagged as a duplicate and routed for review, completely ignoring the filename. This cryptographic deduplication ensured that the repository remained lean and version control remained accurate.
// results
What Changed
The implementation successfully transformed a chaotic, unmanageable shared drive into a rigidly structured, highly predictable document repository. Retrieval times plummeted as employees could suddenly rely on a logical, consistent folder hierarchy. The fail-loud design eliminated the silent accumulation of miscategorized or duplicated files, establishing absolute trust in the system's integrity. Most importantly, the clean, programmatic structure of the repository laid the groundwork for future advanced search interfaces and compliance reporting tools.
Document retrieval
Manual search, minutes
→
0
Consistent
Silent miscategorization
Undetected
→
0
Eliminated
Duplicate handling
Accumulating silently
→
0
Controlled
"The mess stopped compounding. Every document that goes in comes out findable, correctly categorized, and with its conflicts resolved explicitly."