Automation
Social Media Management Suite
One session at a time→Week+ in advancecontent planning horizon
The marketing team was trapped in an operational nightmare, forced to manually log in and post content across multiple social platforms individually. Because timing was dependent on human availability, posts frequently missed peak engagement windows, severely suppressing reach. Furthermore, it was impossible to plan cohesive campaigns because there was no unified interface to view the upcoming content calendar across all networks simultaneously. The worst part was the lack of visibility; tracking performance required manually visiting each platform's analytics dashboard, making cross-platform trend analysis practically impossible. This fragmented process meant the team was entirely reactive, operating without any cohesive strategy.
// system visuals
See It In Action
LIVE_SYSTEM_PREVIEW
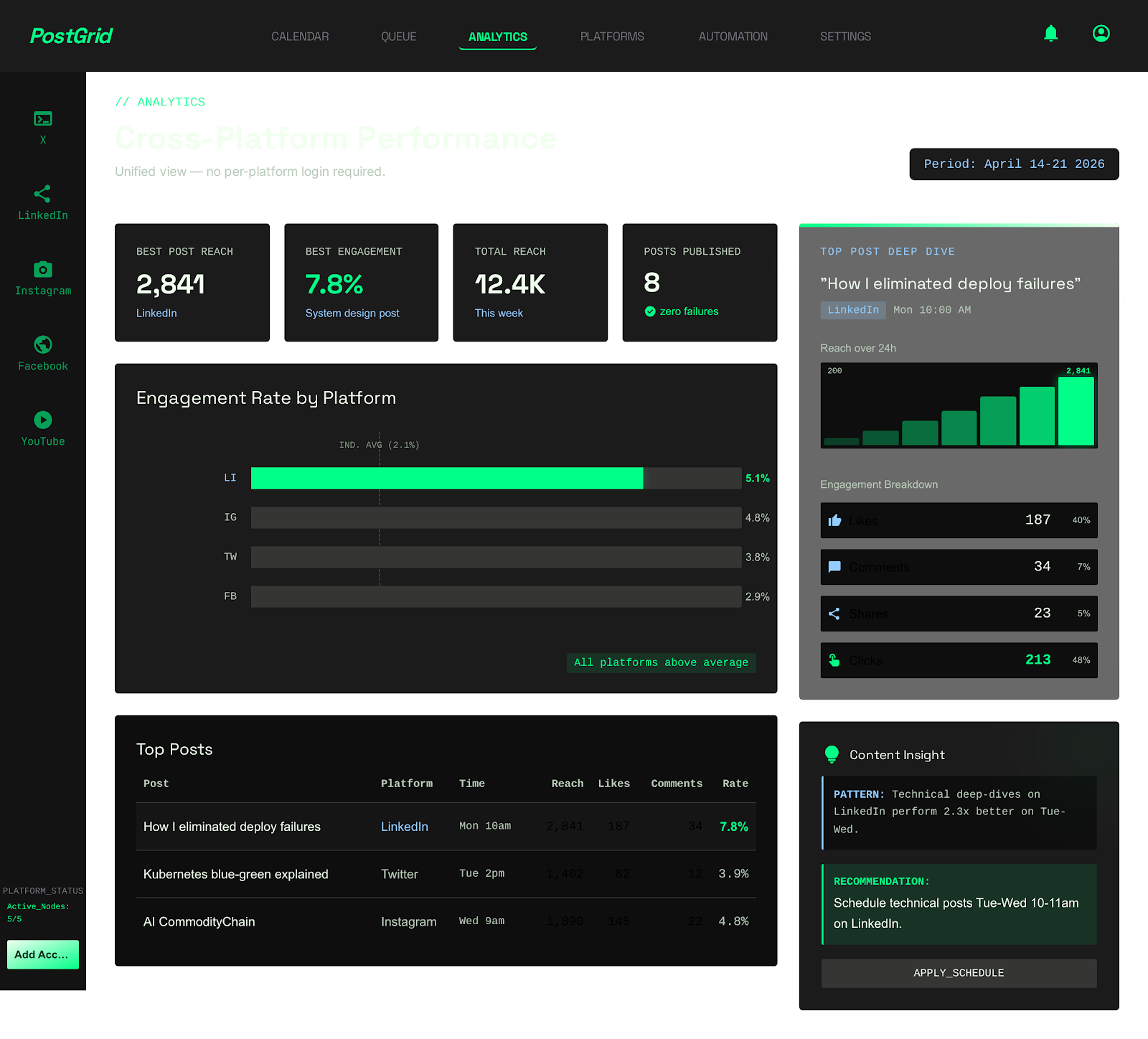
01/02
← → NAVIGATE_SYSTEM
// the problem
What Was Broken
- Posting was entirely manual and platform-specific, meaning content delivery was bottlenecked by a human remembering to log in at the right time. Automated the dispatch process via a centralized scheduling queue, ensuring precise, on-time delivery.
- The team lacked any ability to plan cohesive campaigns beyond a single day because there was no unified view of upcoming content. Built a centralized dashboard that aggregates the entire publishing calendar across all integrated platforms.
- Performance analytics were isolated within each platform's walled garden, rendering cross-platform trend analysis impossible without hours of manual data entry. Engineered scheduled data pipelines to pull engagement metrics into a single, unified database.
- When a manual post failed (e.g., image upload error), the operator knew immediately, but initial automation attempts failed silently, causing campaigns to go dark. Implemented rigorous failure detection and alerting to ensure a missed post is always caught.
// required fix
- Marketing needed a way to plan their entire week in one sitting rather than scrambling daily. The task was to build a robust, durable scheduling queue that stores posts and dispatches them at precise, user-defined times.
- Different platforms require completely different integration strategies. The goal was to build a hybrid dispatch architecture that leverages fast APIs where possible and headless browser automation where necessary.
- Silent failures in automated posting destroy trust in the tool. The objective was to implement strict health checks and explicit alerting mechanisms to immediately notify operators if a scheduled post fails to deploy.
- The team was flying blind regarding cross-platform performance. The task required engineering automated, scheduled data ingestion pipelines to aggregate reach, likes, and shares into a single analytical view.
// solution
How It Was Built
The core of the system is a Python-based centralized scheduler that queues content and coordinates dispatch times via an asynchronous task runner. The dispatch mechanism utilizes a hybrid approach: fast, reliable API calls for platforms like X and LinkedIn, and orchestrated Selenium instances for platforms lacking public APIs. To prevent silent failures, every dispatcher runs a pre-flight health check before attempting to post; if the platform is unreachable or the API token is expired, it aborts and fires an alert. To close the operational loop, the system runs scheduled cron jobs to scrape and aggregate engagement metrics from all integrated platforms back into a unified dashboard.
Hybrid Publishing — API + Selenium
- The most complex engineering challenge was dealing with platforms that do not expose public publishing APIs.
Analytics Feedback Loop
- Posting the content is only half the battle; the team needed to understand how it performed.
Hybrid Publishing — API + Selenium
The most complex engineering challenge was dealing with platforms that do not expose public publishing APIs. For platforms with robust APIs, the system uses standard HTTP libraries to execute fast, authenticated payloads. For restricted platforms, the system spins up headless Selenium instances. These instances are highly orchestrated; they load cookies from encrypted storage, mimic realistic human pacing to avoid bot detection, navigate the DOM to upload media, and verify the post's appearance before tearing down the container. To prevent silent failures, immediately before the scheduler attempts to dispatch a post, it runs a pre-flight health check to verify network connectivity and API token validity. If the dispatch fails, the system aggressively catches the exception, marks the post as 'failed', and immediately fires an alert.
Analytics Feedback Loop
Posting the content is only half the battle; the team needed to understand how it performed. The solution was engineering scheduled ingestion pipelines that run every 12 hours. These pipelines authenticate with the respective platform APIs (or scrape via Selenium) to pull back granular engagement data: reach, impressions, likes, and clicks. This raw data is normalized and stored in a central PostgreSQL database. A unified dashboard then queries this database, presenting the marketing team with a consolidated view of their cross-platform performance. This allowed them to instantly see which type of content resonated best across different networks, transforming their strategy from instinct-driven to data-driven.
// results
What Changed
The suite fundamentally changed how the organization handled social media, moving from reactive, daily manual labor to strategic, long-term planning. The hybrid publishing engine proved highly reliable, ensuring campaigns launched cohesively across all networks simultaneously. By unifying analytics, the team finally achieved cross-platform visibility, drastically accelerating their ability to optimize content. The explicit failure detection eliminated the anxiety of silent drops, resulting in a system the team completely trusted.
Content planning horizon
One session at a time
→
0
Scheduled
Failed post detection
Undetected (silent failure)
→
0
Fail-loud
Analytics visibility
Per-platform manual lookup
→
0
One view
"Content publishing became a planned, reliable operation instead of a reactive manual task."